
想象一款应用突然开始推荐无关商品,或聊天机器人开始传播错误信息。这些故障不仅是技术缺陷,更折射出用户体验与AI模型训练数据之间的脱节。
用户:认知过载的困境
用户在与AI交互时输入的提示词(prompts)——包含指令和上下文——正成为塑造AI输出的关键数据源。当前的交互模式要求终端用户自行构建大部分所需信息结构,这导致用户陷入认知过载的困境。我们必须承认:多数人在与AI对话时并不知道该如何提问。这种责任应该转移给模型设计团队,尤其是UX团队。
UX学科的身份重构
UX设计领域正经历自我认知的革新,争论焦点在于AI时代设计的未来形态。答案其实早已显现——数据(及其相关决策)才是核心。虽然数据看似超出设计师的传统工作范畴,但通过上下文和用户意图的视角审视,一切将豁然开朗。
上下文:人类与AI的共同需求
AI模型与人类一样依赖上下文理解情境。模糊的问题必然导致无效的回答。正如清晰的设计简报是客户沟通的基础,为AI模型提供精准的上下文信息,才能使其生成有价值的响应。
UX团队必须参与模型训练全程
当问题显现在界面层时已难以修复。虽然用户可以进行有限调整,但模型应首先生成最优解。质量优于数量的数据策略同样关键——劣质数据必然导致错误结果(垃圾进,垃圾出)。团队必须在产品上线前主动解决偏见、隐私和价值观偏差等问题。
训练数据的多元形态
提示词(Prompts)
UX设计师Amelia Wattenberger的精辟论断”提示词即语境堆砌”揭示了本质。将任务拆解为黄金提示词(golden prompts)并提供输出示例,已成为UX从业者的新职责。这些提示词的创建、标注和评估过程既复杂又关键,值得专文探讨。
数据集(Datasets)
数据集决定AI的”思维方式”,可体现企业专长、个性与价值观。UX团队需深度参与数据集的意图分析、创建过程以及与使用场景的对齐,无论是人工生成还是AI合成的数据。

框架与指令(Frameworks)
如同AI的指南针,确保输出符合预期目标。既可以是Anthropic宪法式的宏观原则,也可以是具体的应答指南,甚至是需要谨慎处理的话题清单。
反馈评估体系(Evaluation Guides)
建立明确的优质输出标准,通过持续评估确保模型有效性。这个定义文档需要团队共识并动态更新。
规模化挑战与解决方案
海量优质数据需求催生了合成数据(AI生成数据)和第三方数据服务。但两者都需要UX团队制定交付标准,并进行严格的质量抽查。
亟待探索的领域
情境框架(Scenario Frameworks)
Google的PAIR团队开创了情境框架先河,将使用场景、指令和AI提示词有机整合。这种工具能显著提升UX团队的工作效率。

人类参与风险(Human Engagement Risks)
先驱Ovetta Sampson提出的这个概念,要求AI开发者承担消除社会文化偏见的数据责任。不能再以”快速上线”为由忽视边缘案例,对抗训练(adversarial training)和风险情境框架等解决方案亟待开发。设计师的责任从未如此重大。
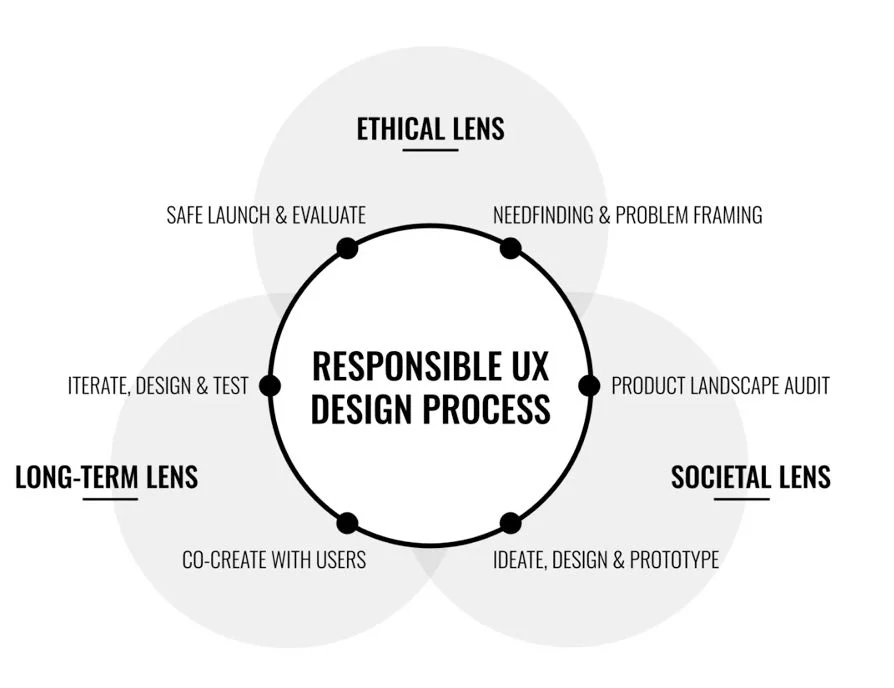
UX团队的新必修课:理解AI工作原理
UX团队必须深度参与模型全生命周期,成为连接用户需求、商业目标与技术实现的关键枢纽。虽然工程师主导模型开发,但他们往往缺乏具体使用场景的深层认知。
正如笔者在《模型设计师的崛起》中所述:界面设计与模型训练的界限正在消融。理解模型训练如何影响输出,已成为设计流程的必要环节。我们不仅要设计界面,更要塑造模型本身。
教育鸿沟亟待填补
当前UX教育在AI训练领域存在严重断层:现有课程要么过于技术化,要么流于表面。虽然业界正在努力搭建知识桥梁,但优质资源的共享仍面临挑战。
对产品相关岗位进行针对性教育投入,是激发创新的关键。只需一点提示词的助力,UX团队就能释放AI模型的全部潜能——这个机会,我们不容错过。