重述确认(Re-stating)是人工智能向用户反馈其所理解输入内容的方式,旨在消除用户在信息检索、内容呈现或系统构建过程中可能产生的理解偏差。
在讨论《Copilot 最佳实践》和《Copilot 报告功能》时,若未提及使Copilot如此实用且流行的关键**LLM “设计模式”**,这些讨论将是不完整的。尽管这些模式常用于Copilot场景,但在任何涉及LLM(大语言模型)或SLM(小语言模型)的UX设计中都值得关注。
注:我将”设计模式”加上引号,是因为我认为它们更接近于”功能特性”而非真正的设计模式。当前LLM的交互界面设计仍处于快速演变阶段,尚未形成稳定的模式。这也正是UX设计与研究领域令人兴奋之处!
现代语言模型最令人惊叹的独特能力之一,是其通过整合多源异构数据和上下文信息所展现出的强大”理解力”。例如,假设您正在驾驶时对模型说了一个词:”Park(停/公园)”。新一代AI可通过访问您的日程表,判断您正接近预定目的地——旧金山市区的一家热门夜店,结合当前时间为晚上9点、天色已暗等背景信息,现代LLM(如ChatGPT)便能推断您需要的是”停车场位置”,而非”国家公园信息”、”植物园游玩建议”或”金门公园骑行路线”:
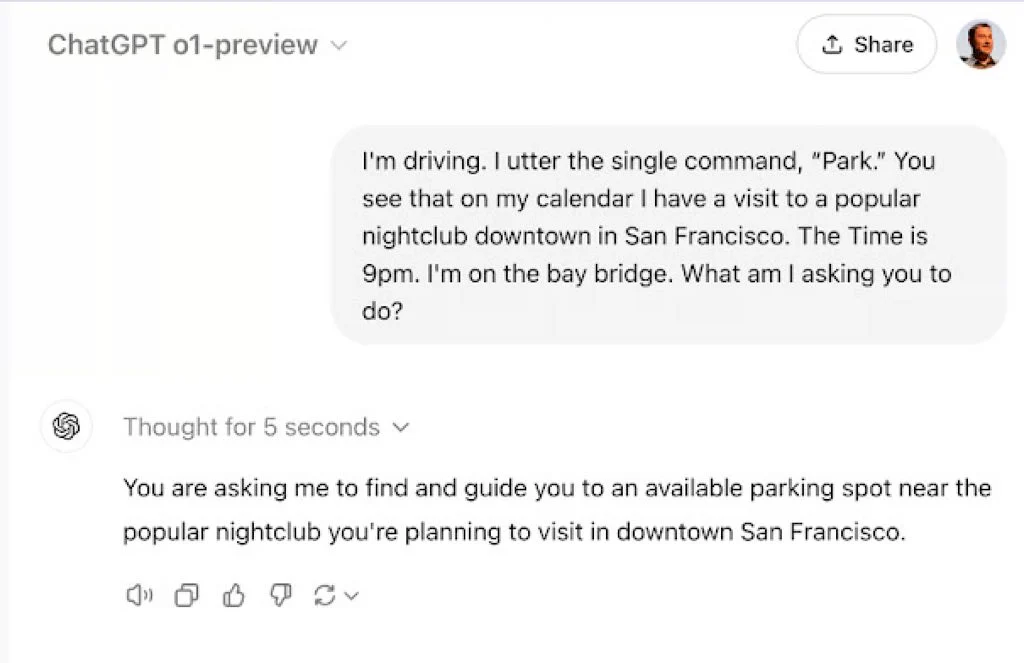
*来源:ChatGPT o1-preview*
相比之下,上一代语音助手(如Siri)则显得笨拙许多。当用户说出”Park”时,Siri只会机械地反问:”Which one?”(您指哪一个?),暴露出其无法结合上下文进行推理的局限性:
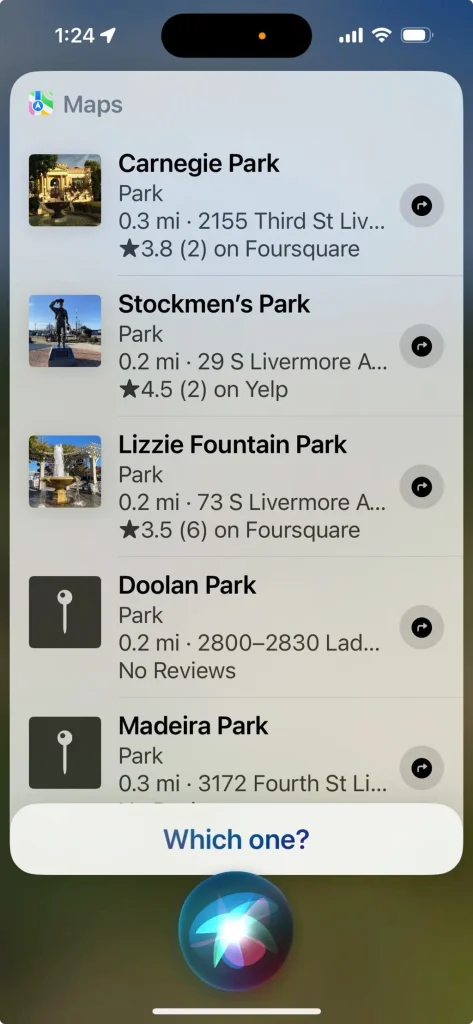
来源:Siri
举此例并非为了嘲讽Siri及其同类产品(如Cortana和Alexa),而是为了突显现代LLM的非凡能力。这提醒我们:采用下文将探讨的设计模式对确保LLM精准执行用户意图至关重要。
正如1921年诺贝尔和平奖得主克里斯蒂安·兰格(Christian Lange)的经典名言:
“科技是忠仆,亦是险主。”
要让LLM始终扮演”忠仆”角色,我们需要掌握重述确认、自动补全、反馈对话、智能建议、步骤拆解、修正微调和安全护栏等关键模式。本周我们将聚焦首个模式——重述确认。
重述确认模式解析
重述确认的本质是AI向用户明确反馈其理解的输入内容。通过在”人-机”界面中应用此模式,可有效消除用户在进行信息检索、内容呈现或系统构建时的理解歧义。该模式最著名的早期应用案例之一是微软Power BI的”自然语言查询(Q&A)”功能,最新示例如下:
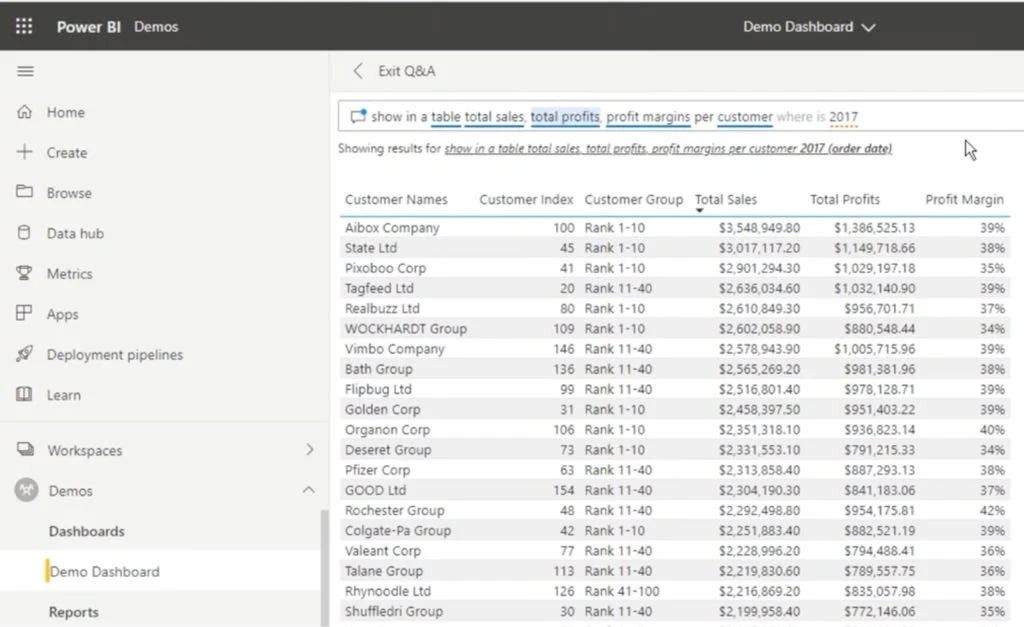
来源:Enterprise DNA《Power BI自然语言查询使用详解(2022版)》
上例中,用户在输入框键入”…where is 2017″,系统立即在输入框下方将其重述为”2017 (order date)”。这种通过重述填补语义空白并自动纠错的功能极具价值——它既包容了人类输入时的疏漏(如打字错误或表述简略),又充分发挥了LLM的核心优势:根据上下文预测合理语义。
何时需要重述确认?
是否应在执行操作前进行重述确认?这需要权衡利弊。
回顾前文《AI准确性是伪命题:UX设计者的破局之道》中提出的”价值矩阵”理论,判断”是否应基于AI推测立即执行操作”需考量两个关键因素:
- AI出错的概率
- 误判带来的负面影响
通过将”幻觉错误”(hallucination)的影响乘以错误回答的数量,即可计算不同方案的ROI(投资回报率)。
以Power BI为例,”自然语言查询”可直接执行,因为误判成本极低(仅产生微量Azure算力费用)。但若将此功能应用于短信解析场景,误判可能导致:
- 发送错误解析的文本内容
- 将短信误发给错误对象
此类误操作的后果可能是灾难性的!因此在这种情况下,系统必须设计确认机制,例如:
“您要求我向老板发送’去你的鸭子(go duck yourself)’,确认发送吗?”